首先明确思路,逐节点的将l1和l2相加,如果遇到需要进位的情况,就单独将所进的位数保存起来,并加到下一次的sum中去,然后在同一次循环中构造好相加后的链表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| ListNode* addTwoNumbers(ListNode* l1, ListNode* l2)
{
ListNode dummy(0);
ListNode* curr = &dummy;
int carry = 0;
while(l1 || l2 || carry != 0)
{
int sum = carry;
if(l1)
{
sum += l1->val;
l1 = l1->next;
}
if(l2)
{
sum += l2->val;
l2 = l2->next;
}
// 进位
carry = sum / 10;
int digit = sum % 10;
curr->next = new ListNode(digit);
curr = curr->next;
}
return dummy.next;
}
|
使用的是双指针
定义左指针left和右指针right,初始都先指向头结点的前一个结点(哨兵节点),然后先将right指针向后移动n的距离,这样当right指针遍历到尾节点时,left指针恰好处于right指针后n个位置,也就是倒数第n个节点。
到达目标位置之后,先将需要删除的节点保存在一个临时变量中,避免内存泄漏,再将上一个节点的指向改为当前节点的下一个节点,最后delete当前节点,并返回头节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| ListNode* removeNthFromEnd(ListNode* head, int n)
{
ListNode dummyNode(0, head);
ListNode* left = &dummyNode;
ListNode* right = &dummyNode;
for(int i = 0; i < n; i++)
{
right = right->next;
}
while(right->next != nullptr)
{
right = right->next;
left = left->next;
}
auto temp = left->next;
left->next = left->next->next;
delete temp;
return dummyNode.next;
}
|
使用的是迭代
就像之前写过的大部分链表的题目一样,要创建一个哨兵节点(前置节点)
首先哨兵节点指向第一个节点,之后进入循环,前置节点指向第二个节点,第一个节点指向第三个节点,最后让第二个节点指向原来的第一个节点,将前置节点指向此时的第二个节点,进入下一次循环
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| ListNode* swapPairs(ListNode* head)
{
if( !head || !head->next ) return head;
ListNode header1(0, head);
ListNode* prev = &header1;
while(prev->next && prev->next->next)
{
auto node1 = prev->next;
auto node2 = prev->next->next;
prev->next = node2;
node1->next = node2->next;
node2->next = node1;
prev = node1;
}
return header1.next;
}
|
使用的是双指针
这里如果使用最原始的方法:如果当前元素与上一个相同则删除(erase),会导致O(n^2)的时间复杂度——————erase()会将删除元素后面的元素向前移动
而这里,我们定义了两个指针,一个慢指针(k),一个快指针(i);将两个指针对应的值进行比较,如果不同,就将慢指针后移,同时将慢指针所指元素覆盖为当前元素
在这个方法中,我们并没有真正执行“删除”操作,而是对数组进行了重新排列,将重复的元素放到数组末尾,因为最终的返回值是有效的数字个数,因此末尾的区域也就会变成垃圾数据,不需要再去关心它们
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| int removeDuplicates(vector<int>& nums)
{
if(nums.empty()) return 0;
int k = 0;
for(int i = 1; i < nums.size(); i++)
{
if(nums[i] != nums[k])
{
k++;
nums[k] = nums[i];
}
}
return k + 1;
}
|
使用到的是哈希表
思路:因为第一次遍历复制各个结点的时候,是不知道后面的节点的,因此一次遍历无法将random元素对应上去,所以一共需要两次遍历:第一次复制所有节点并并对应的random与当前节点绑定,第二次将当前节点的random元素指向对应的成员
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| Node* copyRandomList(Node* head)
{
if(head == nullptr) return nullptr;
Node* curr = head;
std::unordered_map<Node*, Node*> map;
while(curr != nullptr)
{
map[curr] = new Node(curr->val);
curr = curr->next;
}
curr = head;
while(curr != nullptr)
{
map[curr]->next = map[curr->next];
map[curr]->random = map[curr->random];
curr = curr->next;
}
return map[head];
}
|
如图,环外的长度为a,slow指针进入环内走了b才与fast相遇,fast走完了n圈,也就是n(b+c)+ b的距离
根据两者相遇时的时间相同,可以得到等式:a+(n+1)b+nc=2(a+b)⟹a=c+(n−1)(b+c)
当n等于1时,a=c;此时如果放置一个指针从head处向后移动,同时另一个指针从slow与fast相遇的地方以相同的速度沿着c移动,那么两者最终会在环的入口处相遇;至于为什么不考虑n,而是直接取n为1,是因为n仅仅代表着相遇处的指针多走的圈数,最后两者还是会在入口相遇
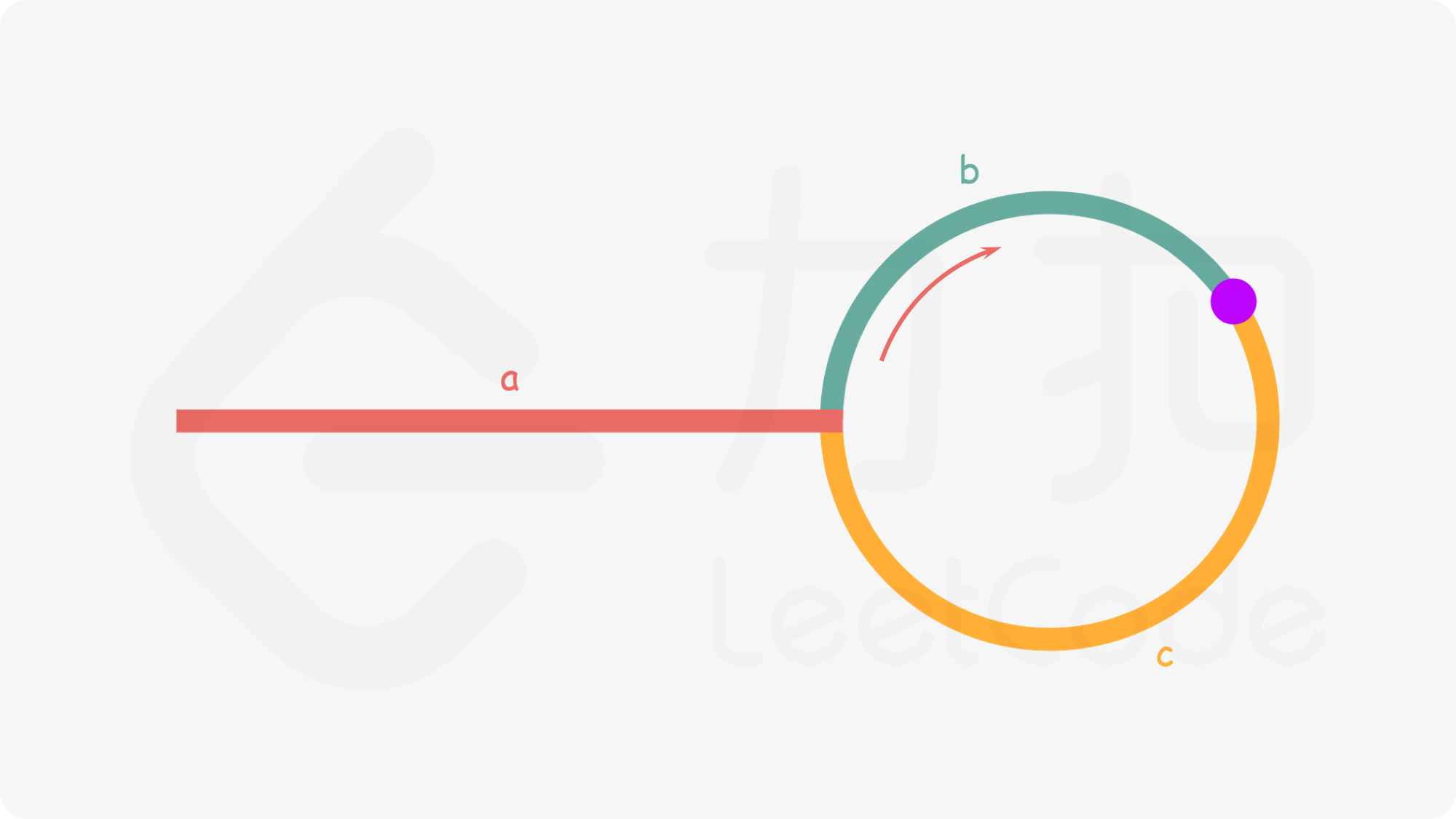
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| ListNode *detectCycle(ListNode *head)
{
if(head == nullptr || head->next == nullptr) return nullptr;
ListNode *slow = head, *fast = head, *p1 = head;
while(fast != nullptr)
{
slow = slow->next;
if(fast->next == nullptr) return nullptr;
fast = fast->next->next;
if(slow == fast)
{
while(p1 != slow)
{
p1 = p1->next;
slow = slow->next;
}
return p1;
}
}
return nullptr;
}
|
解法一:归并排序(分治)
时间复杂度:O(nlogn),空间复杂度:O(logn)
从上至下将链表拆分为长度为一的单链表,然后先对长度为1的链表排序,合并两个链表;
再对长度为2的两个链表排序,之后合并….以此类推,每次排序并合并一半链表,最终就可以得到有序的链表
具体实现:
mergeSort():
在头部定义一个哨兵节点,然后遍历比较left与right的值,如果left更小,就将当前left节点接到哨兵节点后面,并将left向后移动一位,继续比较(right同理);最后当left或者right其中一个为空,也就是该子链表遍历完成时,就直接将另一个链表接到末尾,此时返回的哨兵节点的next就是排序后的链表的头节点
sortList():
在主函数中,需要不断地将链表分为两半(通过递归调用),之后每一层递归都会调用mergeSort函数对当前分割出来的两个链表进行排序,直到最后合成回初始的链表
解法二:归并排序(迭代)
ps:这里我还没看明白,之后再补上………………..
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| class Solution
{
public:
ListNode* mergeSort(ListNode* left, ListNode* right)
{
ListNode* dummyNode = new ListNode(0);
ListNode* trail = dummyNode;
while(left && right)
{
if(left->val < right->val)
{
trail->next = left;
left = left->next;
}
else
{
trail->next = right;
right = right->next;
}
trail = trail->next;
}
if(left)
trail->next = left;
else
trail->next = right;
return dummyNode->next;
}
ListNode* sortList(ListNode* head)
{
if(!head || !head->next) return head;
ListNode *slow = head, *fast = head->next;
while(fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
}
ListNode *second = slow->next;
slow->next = nullptr;
ListNode *first = head;
first = sortList(first);
second = sortList(second);
return mergeSort(first, second);
}
};
|
使用到的是哈希表和链表(重点是链表迭代器)
这题难点在于“逐出最久未使用的关键字”,首先明确思路:既然要求常数时间的复杂度,那么就一定会要用到哈希表(查找),但是又要求有一个数据结构可以存储元素使用的顺序,并且改变顺序时也要是O(1)的时间复杂度,那么就也要使用到链表(通过调用 Splice函数 可以改变迭代器位置,从而在常数时间内实现顺序的改变)
但是如何将哈希表与链表结合起来?答:将value和iterator绑定在一起,这样就通过key就既可以得到value的值,又可以实现iterator的移动
具体实现:
首先拿到最大容量,避免后续多次函数调用产生的开销;
然后开始定义 get 函数:
- 如果哈希表内能够找到对应的key,那么就认为这个元素被访问了一次,因此也就需要将其放在链表的尾部,这里可以通过key在哈希表中找到对应的iterator
- splice()函数的语法之一(移动单个节点):
* **void splice(const_iterator pos, list& other, const_iterator it);**
- 将 `other` 链表中由 `it` 指向的那个元素剪切到 `this` 链表的 `pos` 位置
最后实现 **put **函数:
- 这里有两种情况需要处理:1.当前key已经存在 2.容量已满
- 1.key重复:
* 意味着需要覆写之前的value,将其移至list尾部,这里还是使用到splice()
- 2.容量已满:
* 此时需要删除头节点,直接pop_front()即可;同时也要同步删除哈希表中对应的元素
最后将新插入的元素添加到两个容器即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| class LRUCache
{
public:
LRUCache(int capacity) : capacity(capacity)
{
cache.reserve(capacity);
}
int get(int key)
{
if(cache.contains(key))
{
auto it = cache.find(key);
order.splice(order.end(), order, it->second.second);
return it->second.first;
}
else return -1;
}
void put(int key, int value)
{
auto it = cache.find(key);
if(it != cache.end()) // 如果value已经存在,则更新
{
it->second.first = value;
order.splice(order.end(), order, it->second.second);
return;
}
if(cache.size() >= capacity) // 处理超出容量情况
{
cache.erase(order.front());
order.pop_front();
}
order.push_back(key);
cache[key] = {value, std::prev(order.end())};
}
private :
int capacity;
std::unordered_map<int, std::pair<int, std::list<int>::iterator>> cache; // 键,值,迭代器
std::list<int> order;
};
|